🧭 Pathways to Data Scaling Law of Robotics Foundation Model

2025 can be an exciting year for robotics research. Every day I wake up in the midst of anxiety to check X and make sure that the robotics moment of GPT has not come to render all my research work completely useless.
Assuming that this moment is not going to come in the next 6-12 months, then this blog will help to answer why – from a data perspective, and predict a few alternative pathways to data scaling for Robotics Foundation Model (RFM). Their characteristics are summarized in the table below.
| Pathway | Data Diversity | Immediate Availability | Cost | Domain Gap |
|---|---|---|---|---|
| Internet Data | Rich | Yes | Low | Large |
| Demonstration | Poor | Yes | High | Minimal |
| Generative Simulation | Medium – Rich | No (Soon?) | Medium | Small |
| World Model | Rich | No (Soon?) | High | Medium – Large |
Robotics’ Data Problem
The single most valuable lesson from the success of LLM is that scaling works. Before we are carried away by all the fancy current techniques of RL finetuning (e.g. Deepseek R1), RAG, or inference-time compute, the scaling of data is the single most important thing for RFM to gain rookie-level capabilities.
Some might say that the data for RFM is already readily available – that robot can learn from watching YouTube videos; that you can just show some recording of a people doing household tasks and then the robot can generalize on its own. All that’s left to do is just to prep a denial statement in case YouTube’s legal unit wants any trouble.
Here is how this argument falls apart, and why robotics companies are off to the other options on this list.
Scaling via Internet Data
The single biggest problem of internet data is embodiment gap. Namely, predicting someone do it ≠ doing it by oneself.
The diagram below explains it. When training VLM/LLM, the model’s task is literarily just predicting the next token as if the model was the author of the context. But for RFM, it must also understand the task from the perspective of the robot. In the figure, it means that the RFM not only needs to know that it need to lift the knife to cut the tomato, but also how the robot would move its motors to achieve such functionality. The data for the latter is generally missing from the internet, because it is robot-specific.
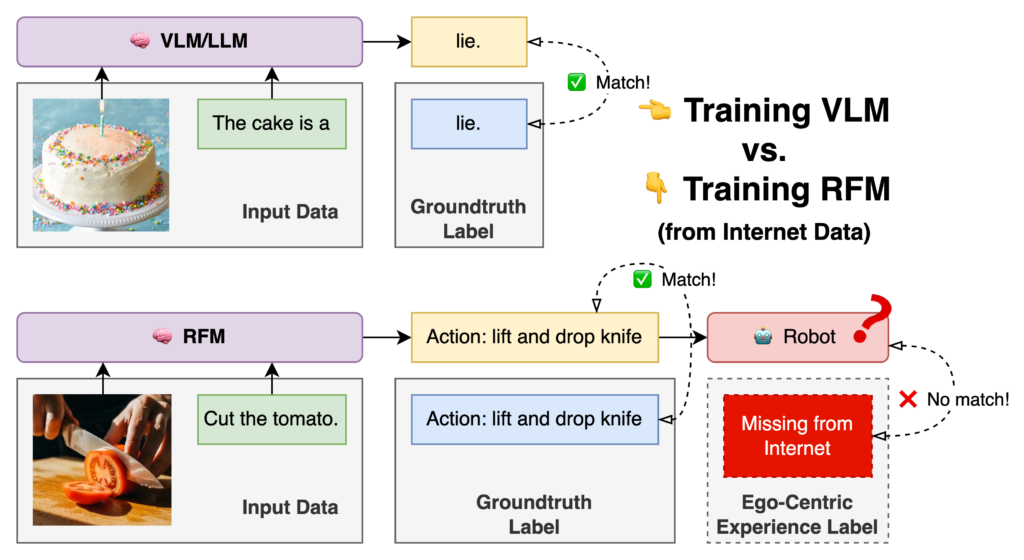
The only embodiment-gap-free data for RFM would be the first-person view and proprioception data from the robot itself, the exact definition of our next option: scaling via demonstration.
However, this does not mean internet data is useless. With the right induction bias and symbolic representation, they can be used to boost the diversity of data and performance in scene understanding during pre-training. In practice, this could mean:
- Use a pre-trained VLM backbone as image and text encoder;
- Train RFM to extract some common representation from internet data that may be helpful for scene understanding. We explored this idea in our recent work ARM4R (using 4D representation): using human videos to boost RFM pre-training performance.
Scaling via Demonstration (Teleoperation)
Teleoperation means hiring a worker to control a robot to perform a task. A bit like puppetry. An example would be the popular Mobile Aloha platform.
Let me restate the motivation for teleoperation as discussed above: teleoperation makes training RFM logically similar to training LLM from a data perspective. With minimal embodiment gap, next token prediction is all you need (maybe plus some diffusion).
Although behavioral cloning is nothing new, the success of LLM in 2023 motivated its scaling and inspired early works such as Aloha and diffusion policy. Now nearly every robotics company either houses a fleet of operators to tele-operate their robots to collect data, or outsources this to emerging robotics data companies.
The only downside of this pathway is the cost. Besides the cost of hosting and operating thousands of robots, there are more alarming issues:
- Cost of data diversity: the more non-standardized, long-tail scenarios the robot needs to cover, the more costly the teleoperation setup will be. You can have a thousand robots collecting cloth-folding data in front of a table this month, but imaging that next month you want them to roll wheelchairs for the elderly outdoor. For more standardized factory and warehouse applications, this is less of an issue; for household and outdoor tasks, it will be problematic.
- Value of data after robot upgrade: if your RFM heavily depends on embodiment-gap-free data, then the teleoperation data becomes less useful every time you upgrade your robot hardware to the next generation (aka a new embodiment), which is rapidly happening at this time when every company is still prototyping for the optimal design to go to market.
In conclusion, I think in the short term, scaling via demonstration is still the most viable pathway, assuming the scaling law for LLM also holds for RFM. However, from this point on, let’s be creative and imagine what new tech can be the game changer for this.
Scaling via Generative Simulation
Out of the two more “novel” pathways to data scaling I’m going to talk about next, generative simulation is the more practical one (and I’m almost certain that some companies with large simulation engineering teams are already working on it).
Basically, if robotics simulations (like IsaacSim and Genesis) can cover as diverse scenarios as possible, then it can be the new “real”. You can ask the simulator, which can have some prompting, function calling, text-to-3D, and procedural generation pipeline, to generate diverse scenes based on your textual and visual description. You can ask the simulation to generate 100 different homes, and ask the tele-operator (wearing some kind of VR and whole-body tracking device) to perform tasks in it.
Early works for this idea is already out there, such as RoboCasa and Genesis. It just requires a good amount of engineering effort to scale it into production level.
The benefits of generative simulation are
- Lower data collection cost: fewer concerns with maintaining a robot fleet, although the value of data after robot model upgrade is still an issue.
- Enabling the collection of privileged information: you can collect information typically not obtainable in real world to guide your policy improvement, such as detailed touch and contact sensing.
- Small embodiment (Sim2Real) gap: simulators are generally good at modeling physical interactions, compared to the world-model scaling method we will discuss next.
- Enabling RL fine-tuning: similar to the Deepseek R1 story, I believe that the right fine-tuning pipeline for robotics is RL, which might be too costly and unsafe to do in real, but easy to do and supervise in simulator.
Downsides of generative simulation includes the upfront R&D cost if it is to be done in-house, and the seemingly unavoidable Sim2Real gap for accurate whole-body control and fine-grained object manipulation. However, I do anticipate the later to be more-or-less resolved in the next year via good research – a topic for another blog post.
Scaling via World Model
The last and most imaginative scaling pathway is world model, which I can give a layman’s definition of “video generation model that is really good at predicting realistic physics” for the purpose of this conversation.
In some sense, world model is the ultimate end-to-end version of generative simulation. The model is directly responsible for rendering the next-frame prediction corresponding to the user’s input. It offers the ultimate flexibility and data diversity in terms of achieving internet-scale data collection.
I’ve drawn the comparison of the two pipelins below. In essence, generative simulation is powered by the physical law of the simulation engine; whereas world model is powered by the generative next-frame-prediction capability.
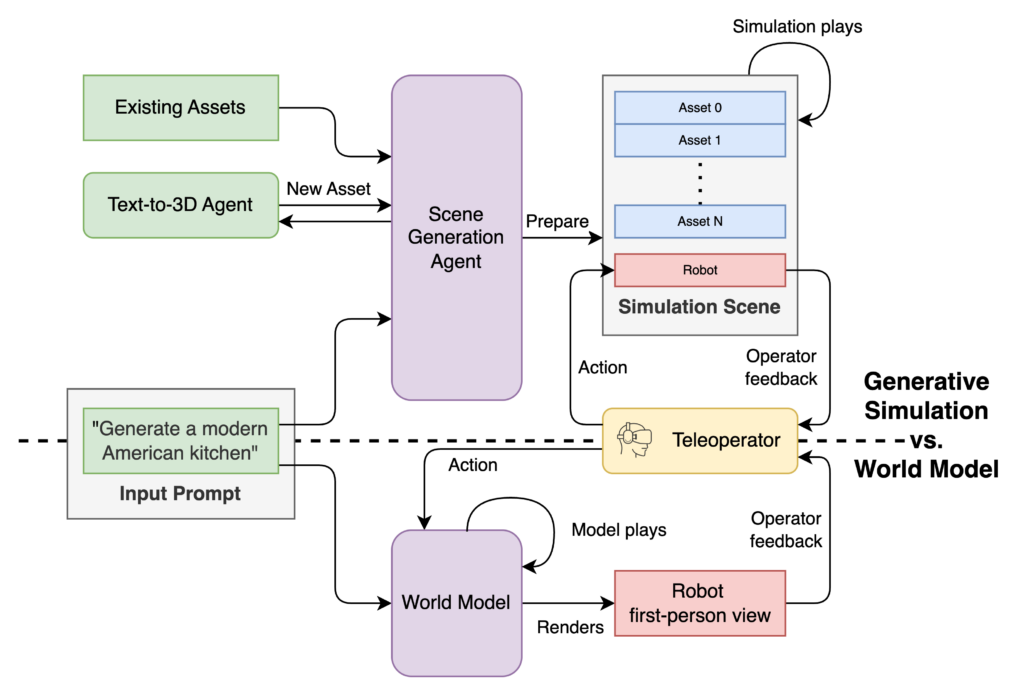
Hell – we might not even need teleoperator in world model. Since the evolution of the world no longer depends on accurate physical input, and world model themselves supposedly can predict evolutions that make the most sense, we can take teleoperation completely out of the loop here. Pre-training can happen directly on synthetic footages. This is somewhat hinted by Figure folks with pre-training their Helix model:
However, the downsides at the current stage is also very obvious:
- Poor physics alignment: video generation models are notoriously bad at keeping perspective consistency and modeling complex physical contacts, which are crucial for robotics data to be useful.
- No access to proprioception and sensory data other than vision: it is not clear yet how to obtain data such as joint angle and contact sensing in the world model pipeline.
My short-term prediction is that, despite not being a viable solution to directly scale data collection, world model (or video generation model with physics understandings) can at least be the next backbone for robotics foundation model, other than VLMs. Because human and animal knowledge of interacting with the physical world shouldn’t need to take the language form, but should rather be something like “day-dreaming in your mind about what will happen next in vivid visual depiction”, which is exactly what world model is doing.
Conclusion
The table summarizing the characteristics of each pathway to robotics data scaling, reproduced for your convenience:
| Pathway | Data Diversity | Immediate Availability | Cost | Domain Gap |
|---|---|---|---|---|
| Internet Data | Rich | Yes | Low | Large |
| Demonstration | Poor | Yes | High | Minimal |
| Generative Simulation | Medium – Rich | No (Soon?) | Medium | Small |
| World Model | Rich | No (Soon?) | High | Medium – Large |
Some explanations:
- Data diversity: the diversity in the tasks included in the data sources
- Immediate Availability: the availability within the next 6 – 18 months
- Cost: Both R&D and data collection cost
- Domain Gap: the gap between the knowledge in the data and the first-hand experience of the robot
My bet on a long-term pathway to robotics data scaling is large-scale world model + generative simulation pretraining, with virtually all the benefits of real-world teleoperation, plus the ability to collect privileged information and do RL fine-tuning. The problem it posts is to fully solve (or minimize) the long-standing Sim2Real discrepancies, and the engineering work needed to production-level generation pipeline.
Like my blog? Subscribe to get a notification!